GDB(GNU Debugger)是UNIX及UNIX-like下的强大调试工具,可以调试ada, c, c++, asm, minimal, d, fortran, objective-c, go, java, pascal等语言。
对于C程序来说,需要在编译时加上-g参数,保留调试信息,否则不能使用GDB进行调试。
直接使用 gdb + 文件名
如果没有调试信息,会提示no debugging symbols found。
如果是下面的提示:Reading symbols from helloWorld...done. 则可以进行调试。
接着进入交互界面 输入命令进行调试
run [参数], 如果运行的程序需要参数 则在run后面直接跟参数即可start默认在最开始有个临时断点
或者使用set args,然后再用run启动
set args用于传递main函数参数show args可以查看参数
调试core文件
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个core文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”)。我们可以认为 core dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。
core dump 对于编程人员诊断和调试程序是非常有帮助的,因为对于有些程序错误是很难重现的,例如指针异常,而 core dump 文件可以再现程序出错时的情景。
当程序core dump时,可能会产生core文件,它能够很大程序帮助我们定位问题。但前提是系统没有限制core文件的产生。
可以使用命令ulimit -c查看是否允许生成core文件
若结果为0 则代表不能生成core文件
可以通过以下命令解除限制 两种方式可选其一。第一种无限制,第二种指定最大产生文件的大小。
ulimit -c unlimied #表示不限制core文件大小
ulimit -c 10 #设置最大大小,单位为块,一块默认为512字节
使用core文件:
(gdb) core-file core # 查看生成的core文件
调试已运行程序
首先使用 ps 命令找到进程id
接着用 attach + id 启动调试
ps -ef|grep 进程名
$ gdb
(gdb) attach 20829
断点设置
Gdb模式下可以使用info break查看已设置断点 或者简写为 i b
根据行号设置断点:
b/break 9 # break 可简写为b
b test.c: 9 # 程序运行到第9行的时候会断住
根据函数名设置断点:
b printNum # printNum 为函数名 程序在调用到printNum函数的时候会断住
根据条件设置断点:
假设程序某处发生崩溃,而崩溃的原因怀疑是某个地方出现了非期望的值,那么你就可以在这里断点观察,当出现该非法值时,程序断住。这个时候我们可以借助gdb来设置条件断点
break test.c:23 if b==0 # 当在b等于0时,程序将会在第23行断住。
或者condition有着类似的作用,假设上面的断点号为1,那么:
condition 1 b==0 # 会使得b等于0时,产生断点1
根据规则设置断点 rbreak
对所有以printNum开头的函数都设置断点,可以使用下面的方式:
rbreak printNum* # 所有以printNum开头的函数都设置了断点
设置临时断点 tbreak
tbreak test.c: 10 #在第10行设置临时断点
跳过多次设置断点 ignore
假如有某个地方,我们知道可能出错,但是前面30次都没有问题,虽然在该处设置了断点,但是想跳过前面30次:
ignore 1 30 # 1为断点号 30是跳过次数
根据表达式值变化产生断点 watch
watch a # 当变量a的值变化时 中断并打印a的值
rwatch 和 awatch 同样可以设置观察点
前者是当变量值被读时断住,后者是被读或者被改写时断住。
禁用或启动断点
disable # 禁用所有断点
disable bnum # 禁用标号为bnum的断点
enable # 启用所有断点
enable bnum # 启用标号为bnum的断点
enable delete bnum # 启动标号为bnum的断点,并且在此之后删除该断点
断点清除
clear # 删除当前行所有breakpoints
clear function # 删除函数名为function处的断点
clear filename: function # 删除文件filename中函数function处的断点
clear lineNum # 删除行号为lineNum处的断点
clear filename:lineNum # 删除文件filename中行号为lineNum处的断点
delete # 删除所有breakpoints,watchpoints和catchpoints
delete bnum # 删除断点号为bnum的断点
变量查看
普通变量查看
使用print(可简写为p)打印变量内容
p a # 打印变量a的内容
有时候,多个函数或者多个文件会有同一个变量名,这个时候可以在前面加上函数名或者文件名来区分
p 'main'::b
打印指针指向内容
使用解引用方式打印
p *d # 通过解引用符*来打印指针指向的内容
但直接使用*仅仅只能打印第一个值
如果要打印多个值(如数组),后面跟上@并加上要打印的长度。
p *d@10 # 通过指针打印一个长为10的数组
$ 可表示上一个变量
假设此时有一个链表linkNode,它有next成员代表下一个节点,则可使用下面方式不断打印链表内容:
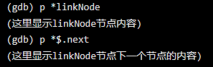
使用 set 可以定义一个变量
如果想要查看前面数组的内容,可以定义下标变量后, 将下标一个一个累加
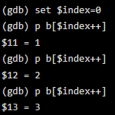
按照特定格式打印变量
对于简单的数据,print默认的打印方式已经足够了,它会根据变量类型的格式打印出来,但是有时候这还不够,我们需要更多的格式控制。
/x按十六进制格式显示变量。/d按十进制格式显示变量。/u按十六进制格式显示无符号整型。/o按八进制格式显示变量。/t按二进制格式显示变量。/a按十六进制格式显示变量。/c按字符格式显示变量。/f按浮点数格式显示变量。

但是这种方式仍然无法查看浮点数的二进制格式,因为直接打印它首先会被转换成整型
查看内存内容
examine(简写为x) 可以用来查看内存地址中的值。语法如下:
x/[n][f][u] addr
n表示要显示的内存单元数,默认值为1.f表示要打印的格式,前面已经提到了格式控制字符u表示要打印的单元长度 单元长度常见有如下:b字节h半字,即双字节w字,即四字节g八字节
addr内存地址

此处 n=4, f = t , u = b
代表以二进制形式打印四个字节大小的e变量所处地址的内存单元中的内容
查看寄存器内容 info registers
自动显示变量内容
假设我们希望程序断住时,就显示某个变量的值,可以使用display
display e # 每次程序断住时,就会打印e的值
要查看哪些变量被设置了display,可以使用:info display
如果想要清除打印变量
delete display [num] # num为前面变量前的编号,不带num时清除所有。
单步调试
单步执行
next命令(可简写为n)用于在程序断住后,继续执行下一条语句。
假设已经启动调试,并在第12行停住,如果要继续执行,则使用n执行下一条语句。
如果后面跟上数字num,则表示执行该命令num次,就达到继续执行n行的效果了
单步进入
step命令(可简写为s),它可以单步跟踪到函数内部,但前提是该函数有调试信息并且有源码信息
如果没有函数调用,s的作用与n的作用并无差别,仅仅是继续执行下一行。它后面也可以跟数字,表明要执行的次数。
继续执行到下一个断点
continue命令(可简写为c)或者fg,它会继续执行程序,直到再次遇到断点处
继续运行到指定位置
假如我们在25行停住了,现在想要运行到29行停住
可以使用until命令(可简写为u)它利用的是临时断点。
跳过执行
skip可以在step时跳过一些不想关注的函数或者某个文件的代码
skip function add # step时跳过add函数
info skip # 查看step情况
skip也后面也可以跟文件:
skip file gdbStep.c
这样gdbStep.c中的函数都不会进入。
skip delete [num]删除skip条目,nun表示跳过条目的编号skip enable [num]启用skip条目,nun表示跳过条目的编号skip disable [num]禁止skip条目,nun表示跳过条目的编号
查看源码或对源码进行编辑
查看源码内容
list(可简写为l),它可以将源码列出来
直接输入 l 可从第一行开始显示源码,未显示全继续输入 l ,可列出后面的源码。
后面也可以跟上 + 或者 - ,分别表示要列出上一次列出源码的后面部分或者前面部分。
l -
l +
l 后面可以跟行号,表明要列出某行附近的源码
l 9
列出指定函数附近的源码: l后面跟函数名即可
设置源码一次列出行数
默认是10行 可以通过set listsize属性来设置

若设置为0或者unlimited,列出就没有限制了,但源码如果较长,查看将会不便。
列出指定行之间的源码
list first,last
启始行和结束行号之间用逗号隔开。两者之一也可以省略,例如:list 3,
省略结束行的时候,它列出从开始行开始,到指定大小行结束,而省略开始行的时候,到结束行结束,列出设置的大小行,例如默认设置为10行,则到结束行为止,总共列出10行。
列出指定文件的源码
l location 其中location可以是 文件名加行号 或 函数名
l test.c: 1 # 查看指定文件指定行
l test.c: printNum1 # 指定文件指定函数
l test.c: 1, test.c: 3 # 指定文件指定行之间
更换源码目录
例如,你编译好的程序文件,放到了另外一台机器上进行调试,或者你的源码文件全都移动到了另外一个目录,怎么办呢?
可以使用dir命名指定源码路径
dir ./temp # 或者使用下面的方式替换当前路径
set substitute-path from [ ] to [ ] # 将原来的路径替换为新的路径
借助 readelf (bash)命令可以知道原来的源码路径
readelf main -p .debug_str
编辑源码
为了避免已经启动了调试之后,需要编辑源码,又不想退出,可以直接在gdb模式下编辑源码,它默认使用的编辑器是/bin/ex,但是你的机器上可能没有这个编辑器,或者你想使用自己熟悉的编辑器,那么可以通过下面的方式在bash下进行设置:
EDITOR=/usr/bin/vim
export EDITOR
使用edit location 可以在调试模式下编辑源码
edit 3 #编辑第三行
edit printNum #编辑printNum函数
edit test.c: 5 #编辑test.c第五行
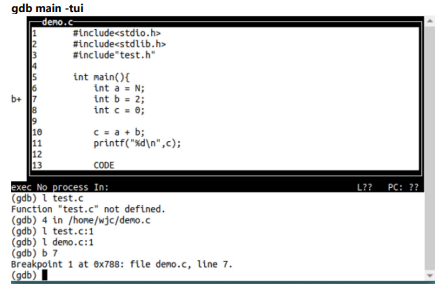
启动时,如果带上tui(Text User Interface)参数,会有意想不到的效果,它会将调试在多个文本窗口呈现: