I/O 多路复用(也叫I/O 多路转接)使得程序能同时监听多个文件描述符,能够提高程序的性能,Linux 下实现 I/O 多路复用的系统调用主要有 select、poll 和 epoll。
常见的I/O模型
计算机中的I/O指的是输入(Input)与输出(Output)
Input:将文件中的内容写入到内存中
Output:将内存中的内容写入到文件中
阻塞 I/O (BIO)
阻塞 I/O 是最常见的 I/O 模型之一,它的特点是在阻塞 I/O 模型中,应用程序会一直阻塞在 I/O 操作上,直到数据准备好或超时。
阻塞 I/O 模型的优点是简单易用,不占用CPU宝贵的时间片,适用于处理低并发量的应用程序。但是,它的缺点是同一时刻只能处理一个操作,效率低下,因为在等待 I/O 操作完成时,CPU 会一直处于空闲状态,无法处理其他任务。
常见的BIO模型方法是通过多线程或多进程去处理客户端请求,每个线程/进程对应一个客户端
- 优点是可以并发处理客户端请求
- 缺点是线程/进程本身会消耗系统资源,调度也需要额外的资源
非阻塞 I/O(NIO)
非阻塞 I/O 是一种改进的 I/O 模型,它的特点是在进行 I/O 操作时不会阻塞应用程序,而是立即返回。在非阻塞 I/O 模型中,应用程序需要不断地轮询 I/O 操作的状态,直到数据准备好或发生错误。
每次循环内的复杂度是O(n),n为连接的客户端数,因为每次循环都得遍历所有客户端的连接以读取可能发送的数据,而事实上并不是每次循环都有数据到达。
非阻塞 I/O 模型的优点是效率高,因为应用程序可以在等待 I/O 操作完成时处理其他任务。但是,它的缺点是编程复杂度高,需要不断地轮询 I/O 操作的状态,会增加代码的复杂度和维护成本。
I/O 多路复用
I/O 多路复用是一种高效的 I/O 模型,它的特点是可以同时监视多个 I/O 操作的状态,当有数据准备好时立即返回。在 I/O 多路复用模型中,应用程序可以使用 select()、poll() 或 epoll() 等系统调用来同时监视多个 I/O 操作的状态。
select()/poll()调用让应用程序可以将数据监测委托给内核,从而高效率地处理I/O操作。但是select调用只会通知有几个文件获得了数据,但具体是哪几个,还需要程序自己遍历二进制查找。
epoll() 系统调用则会直接通知具体是哪几个文件获得了数据
通过这些系统调用,可以将多个IO操作委托给内核,应用程序只需一次系统调用即可完成对多个IO操作的执行。
I/O 多路复用模型的优点是效率高,可以同时处理多个 I/O 操作,避免了轮询的开销。但是,它的缺点是编程复杂度高,需要使用系统调用来实现,代码的复杂度和维护成本都比较高。
异步 I/O
异步 I/O 是一种高级的 I/O 模型,它的特点是在进行 I/O 操作时不会阻塞应用程序,而是立即返回,并在操作完成后通知应用程序。在异步 I/O 模型中,应用程序需要使用 aio_read()、aio_write() 等系统调用来发起异步 I/O 操作,并使用回调函数来处理操作完成后的数据。
异步 I/O 模型的优点是效率高,可以在不阻塞应用程序的情况下进行 I/O 操作,避免了轮询和阻塞的开销。但是,它的缺点是编程复杂度非常高,需要使用系统调用和回调函数来实现,代码的复杂度和维护成本都非常高。
select
select的流程:
- 首先要构造一个关于文件描述符的列表,将要监听的文件描述符添加到该列表中。
- 调用一个系统函数,监听该列表中的文件描述符,直到这些描述符中的一个或者多个进行I/O操作时,该函数才返回。
a. 这个函数是阻塞
b. 函数对文件描述符的检测的操作是由内核完成的 - 在返回时,它会告诉进程有多少(哪些)描述符要进行I/O操作。
关键API
#include <sys/select.h>
int select(int nfds,fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout) ;
- 参数:
- nfds : 委托内核检测的最大文件描述符的值 + 1
- readfds : 要检测的文件描述符的读的集合,委托内核检测哪些文件描述符的读的属性
- 对应的是对方发送过来的数据,因为读是被动的接收数据,检测的就是读缓冲区
- 是一个传入传出参数
- fd_set 本质上是个长为128的long int数组,表示1024个bit位
- writefds : 要检测的文件描述符的写的集合,委托内核检测哪些文件描述符的写的属性
- 委托内核检测写缓冲区是不是还可以写数据(不满的就可以写)
- exceptfds : 检测发生异常的文件描述符的集合
- timeout : 设置的超时时间
struct timeval {
long tv_sec; /* seconds */
long tv_usec; /* microseconds*/
};
- NULL :永久阻塞,直到检测到了文件描述符有变化
- tv_sec=0 tv_usec=0,不阻塞
- tv_sec > 0 tv_usec > 0,阻塞对应的时间
-返回值为一个整数n:
- n = -1 : 失败
- n > 0 : 检测的集合中有 n 个文件描述符发生了变化
这里都是对文件描述符的集合进行操作,而这些集合是用二进制位表示的,下面介绍对文件描述符的集合进行操作的函数
//将参数文件描述符fd对应的标志位设置为0
void FD_CLR(int fd, fd_set *set);
//判断fd对应的标志位是0还是1,返回值: fd对应的标志位的值
int FD_ISSET(int fd, fd_set *set);
//将参数文件描述符fd对应的标志位,设置为1
void FD_SET(int fd, fd_set *set);
// fd_set一共有1024 bit,全部初始化为0
void FD_ZERO(fd_set *set) ;
举例解释
假设客户端A,B,C,D连接到服务器分别对应文件描述符3, 4, 100, 101
对应的我们设置对应的文件描述符集合位,接着调用select检测是否有数据发送
fd_set reads;
FD_SET(3, &reads);
FD_SET(4, &reads);
FD_SET(100, &reads);
FD_SET(101, &reads);
select(101+1,&reads,NULL,NULL,NULL);
遍历每个需要的文件标志位,使用FD_ISSET判断对应文件位是否有数据
有的话则读取数据
遍历完成,在下一次检测之前,使用FD_ZERO将所有位置为0
select执行的过程中,将reads拷贝到内核态,处理完成后将结果又从内核态拷贝到reads中
返回的结果保存在传入变量reads中,其中若该位被置为1则表示有数据,若为0则表示没有数据。
服务器端代码
#include <stdio.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/select.h>
int main(){
int lfd = socket(PF_INET,SOCK_STREAM,0);
struct sockaddr_in saddr;
saddr.sin_port = htons(9999);
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr = INADDR_ANY;
bind(lfd,(struct sockaddr *)&saddr,sizeof(saddr));
listen(lfd, 8);
fd_set rdset, tmp;
FD_ZERO(&rdset);
FD_SET(lfd,&rdset);
int maxfd = lfd;
while(1){
tmp = rdset;
int ret = select(maxfd+1,&tmp,NULL,NULL,NULL);
if(ret==-1){
perror("select");
exit(-1);
}
else if(ret==0) continue;
else if(ret>0){
if(FD_ISSET(lfd,&tmp)){
//表示有新的客户端连接进来
struct sockaddr_in caddr;
int len = sizeof(caddr);
int cfd = accept(lfd,(struct sockaddr *)&caddr, &len);
FD_SET(cfd,&rdset);
maxfd = maxfd>cfd?maxfd:cfd;
}
for(int i = lfd+1;i<=maxfd;i++){
if(FD_ISSET(i,&tmp)){
char buf[1024] = {0};
int len = read(i,buf,sizeof(buf));
if(len==-1){
perror("read");
exit(-1);
}
else if(len==0){
printf("客户端%d关闭\n",i);
FD_CLR(i,&rdset);
close(i);
}
else if(len>0){
printf("读取数据:%s\n",buf);
write(i,buf,strlen(buf)+1);
}
}
}
}
}
close(lfd);
}
select 缺点:
- 每次调用
select, 都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时
会很大 - 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时
也很大 - select支持的文件描述符数量太小了,默认是1024
- fds集合不能重用,每次都需要重置
poll
poll是对select的一个改进,主要区别在于将fd集合封装成一个结构体,从而使得集合可以被重用,并且也没有大小限制了
关键API
#include <poll.h>
struct pollfd {
int fd; /*委托内核检测的文件描述符*/
short events; /*委托内核检测文件描述符的什么事件 */
short revents ; /*文件描述符实际发生的事件,即返回的结果*/
};
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
- 参数:
- fds : 是一个struct pollfd 结构体数组,这是一个需要检测的文件描述符的集合
- nfds : 这个是第一个参数数组中最后一个有效元素的下标+ 1
- timeout : 阻塞时长
0 : 不阻塞
-1 : 阻塞,当检测到需要检测的文件描述符有变化,解除阻塞
>0 : 阻塞的时长
- 返回值为n:
-1 : 失败
>0 : 成功,, n表示检测到集合中有n个文件描述符发生变化
events的取值如下:
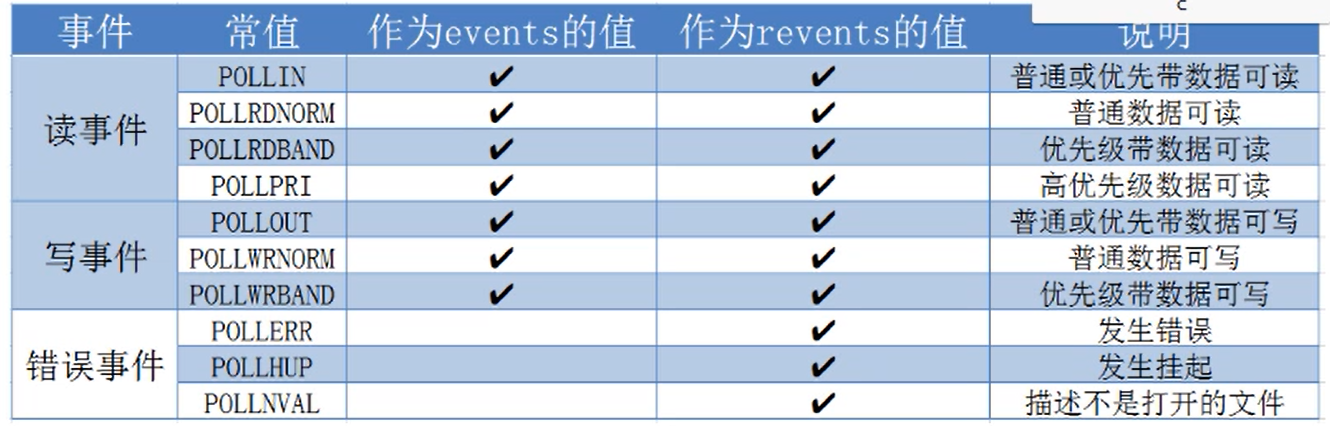
如果要同时检测多个事件 使用 | 连接
struct pollfd myfd;
myfd.fd = 5;
myfd.events = POLLIN | POLLOUT;
服务器端代码
#include <stdio.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <poll.h>
int main(){
int lfd = socket(PF_INET,SOCK_STREAM,0);
struct sockaddr_in saddr;
saddr.sin_port = htons(9999);
saddr.sin_family = AF_INET;
saddr.sin_addr.s_addr = INADDR_ANY;
bind(lfd,(struct sockaddr *)&saddr,sizeof(saddr));
listen(lfd, 8);
struct pollfd fds[1024];
for(int i=0;i<1024;i++){
fds[i].fd = -1; //初始化为-1表示未打开状态
fds[i].events = POLLIN; //初始化检测读事件,即有数据到达读缓冲区
}
fds[0].fd = lfd;
int nfds = 1;
while(1){
//调用poll函数 检测描述符集合
int ret = poll(fds,nfds,-1);
if(ret==-1){
perror("select");
exit(-1);
}
else if(ret==0) continue;
else if(ret>0){
if(fds[0].revents & POLLIN){
//表示有新的客户端连接进来
struct sockaddr_in caddr;
int len = sizeof(caddr);
int cfd = accept(lfd,(struct sockaddr *)&caddr, &len);
for(int i=1;i<1024;i++){
if(fds[i].fd==-1){
fds[i].fd = cfd;
fds[i].events = POLLIN;
if(nfds<i+1) nfds = i+1;
break;
}
}
}
for(int i = 1;i<nfds;i++){
if(fds[i].revents & POLLIN){
char buf[1024] = {0};
int len = read(fds[i].fd,buf,sizeof(buf));
if(len==-1){
perror("read");
exit(-1);
}
else if(len==0){
printf("客户端关闭\n");
close(fds[i].fd);
fds[i].fd = -1;
}
else if(len>0){
printf("读取数据:%s\n",buf);
write(fds[i].fd,buf,strlen(buf)+1);
}
}
}
}
}
close(lfd);
}