STL介绍
容器和泛型算法都属于STL模板库 其第一个实现版本是HP STL ,而且开放源代码
现在最常用的是SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现 被Linux的C++编译器GCC所采用,SGI STL是开源软件
P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的
顺序容器类型
一个容器就是一些特定类型对象的集合
顺序容器提供了控制元素储存和访问顺序的能力 这种顺序只与元素加入容器的位置相对应
顺序容器包括:
vector(可变大小 连续内存 随机访问 在尾部之外插入删除很慢)string(类似于vector的字符专用版)deque(队列 随机访问 在头尾插入删除快)list(双向链表 只能双向顺序访问 任何位置插入删除都快),forward_list(单向链表)array(固定大小数组 随机访问 不可插入删除)
string和vector由于连续储存元素 保存在连续内存中 故可以快速随机访问
但时在中间插入删除时必须 移动前/后的所有元素 因此非常耗时
deque与vector和string类似 支持快速随机访问 中间位置添加删除慢
但它在头尾插入删除都快 和链表速度差不多
链表类型可以内存不连续 通过指针链接使任何位置的插入删除都很快 但是只能顺序访问遍历容器 还需要额外内存开销保存指针
单向链表没有size操作 访问 list 容器中存储元素的方式很有限,即要么使用 front() 和 back() 成员函数,要么使用list 容器迭代器。
array数组类似于内置数组 但性能更优化 可以支持对象拷贝和赋值操作
和内置数组类似 在构造时除了要指定元素类型 还必须指定数目
默认是非空的 包含初始指定数目的元素 自动初始化
array< int, 32> arr;
一般来说 都使用vector作为顺序容器 除非有特别的理由
构造函数
假设容器类型为C,容器的构造函数有:
C c; //默认构造函数 构造空容器
C c1(c2); //拷贝构造
C c(b, d); // 以迭代器b和d指定的范围拷贝元素构造c
C c{a,b,d,e…}; //以列表初始化构造c
顺序容器(不包括array)还特有两个构造方法:
C c(n); //指定元素个数 自动值初始化
C c(n, t); //指定包含n个初始值为t的元素
当以拷贝容器初始化构造或者拷贝赋值时 两个容器的类型和元素类型都必须相同
注意 string 和 const char * 是不同的
但是通过范围拷贝元素构造时可以不相同 只要可以通过转换得到就行
并且顺序容器额外支持通过.assign()将某个范围内不同但可转换的元素类型赋值给容器
或者通过assign用指定数目的相同值替换容器中的所有原有元素
a.assign(b.begin(), b.end());
a.assign(10,"hi");
反向容器(不支持forward_list)
可以通过reverse_iterator得到按逆序寻址元素的迭代器
通过c.rbegin() 和 c.rend() 返回指向尾元素和首元素之前位置的迭代器 对应于c.begin()和c.end()
同样 c.crbegin() 和 c.crend() 是对应的常量版本
注意 迭代器范围是个左闭合区间 [begin,end), end指向的是尾元素(反向容器是首元素)之后的位置
赋值操作
所有容器都支持直接赋值
c1=c2;
c1= {a,e,d,…};
可通过swap函数交换容器的值
c1.swap(c2);
swap(c1,c2);
//两种方法都行 最好使用后一种
使用swap时并不真正移动容器中元素的位置(array除外)
而是交换容器的内部结构 因此都可以在常数时间内完成
对array使用swap时 会真正交换它们的元素 因此耗时与array中元素的数目成正比
容器可通过.size()返回当前大小
.max_size()返回可保存的最大元素数目
.empty()返回是否为空
迭代器访问
所有容器的迭代器都支持++和*
并通过解引用操作*来访问容器元素
只有单向链表的迭代器不支持递减操作 --
对于反向容器迭代器而言 ++意味着访问上一个元素 --同理
支持随机访问的容器(string vector deque array)的迭代器才支持部分算术运算
利用auto与begin或end结合使用时 可以根据容器类型自动获得对应版本的迭代器 而不用显式指定类型
当然 也可以用cbegin或cend来显式指定
auto it1 = a.begin(); // it1的类型取决于a是否是常量 自适应
auto it2 = a.cbegin(); // it2是const_iterator
成员函数
所有容器都支持 == 和 !=
除了无序关联容器以外 都支持关系运算符 > >= < <=
但关系运算符两侧必须是同一种元素类型的同一种容器
比较时
- 若容器大小和元素内容都相同 则相等;
- 若容器大小不同 但容器小的那个是大的前缀子序列 则较小容器小于较大容器;
- 前两者都不符合时 比较第一个不同的元素大小
注意 必须容器中的元素都定义了关系运算 容器才能使用关系运算
顺序容器通过 push_back() push_front() insert() 来插入拷贝的元素 (单链表不支持push_back()和insert())
对应的新标准有 emplace_back() emplace_front() emplace()
来插入根据输入参数新构造的对象
通过front() 和back() 可以直接返回首元素和尾元素的引用
下标操作[n]等价于at(n) 但是at函数会在下标越界时抛出异常
通过 pop_back() pop_front() erase() 来删除容器中的元素
clear()可以清空容器中的元素
单链表不支持pop_back()和 erase()
通过resize()可以改变容器大小 当前大小大于要求则会删除多余元素 小于时则会添加新元素到容器尾部
c.resize(n);
c.resize(n, t); //对于新添加的元素可以指定值
单向链表比较特殊 我们必须提供其前驱来删除或插入对应位置的元素
其使用函数也不同 before_begin() 对应于普通的begin() 返回的是首元素之前的位置或者说头指针
插入元素 insert_after(p, …) emplace_after(p,…) 在p迭代器之后的位置插入元素
删除元素 erase_after() 同理
添加或删除容器中的元素可能会导致指向容器中元素的指针 迭代器和引用失效
在改变容器大小的循环中 必须保证每个循环内都更新迭代器
insert和erase操作本身就返回迭代器 容易更新
而使用end时 必须每次都重新调用更新 保存尾迭代器的值是一个坏主意
通过capacity()可以获取当前vector或string分配的空间
reserve(n)可以主动申请分配至少n个元素的空间
只有当当前容量不足以添加新的元素时 才会申请分配新的空间
string对象可以通过substr()获取指定位置的子串
通过find()可以搜索指定字串(大小写敏感) rfind()逆向搜索
通过append()可以追加字符串
通过stoi(),stol(),stod(),stoul,stof()等函数实现string到其他类型如int long double unsigned long等的转换
通过to_string()可以实现其他类型到string的转换
适配器
适配器是一种机制 使得某个容器类型看起来像另一种类型
如stack queue 和 priority_queue 分别是栈, 队列和优先队列适配器
它们定义了对应的操作 并且只能执行对应操作 而不能执行其底层容器的操作
可以自己定义适配器的底层容器
Stack<int, vector<int>> dp;
//注意 stack 和 queue在缺省状态下都是采用deque为底层容器的
priority_queue 其实就是一个披着队列外衣的堆
因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式,看起来就是一个队列。
优先级队列内部元素是自动依照元素的权值排列。
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
priority_queue 模板有 3 个参数,其中两个有默认的参数;第一个参数是存储对象的类型,第二个参数是存储元素的底层容器,第三个参数是函数对象类(注意一定是个类)
function 头文件中定义了 greater
例如我们在写快排的cmp函数的时候,return left>right 就是从大到小,return left<right 就是从小到大。
但优先级队列的定义正好反过来了 return left>right 就是小堆 return left<right 就是大堆
适配器操作 :
push对应push_backpop对应pop_back()front()和back()是一致的
栈里面的元素在内存中是连续分布的么?
这个问题有两个陷阱:
陷阱1:栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中是不是连续分布。
陷阱2:缺省情况下,默认底层容器是deque,那么deque的在内存中的数据分布是什么样的呢? 答案是:不连续的,deque的底层实现和 vector 容器采用连续的线性空间不同,deque 容器存储数据的空间是由一段一段等长的连续空间构成,但各段空间之间并不一定是连续的,可以位于在内存的不同区域。
为了管理这些连续空间,deque 容器用数组(数组名假设为 map)存储着各个连续空间的首地址。也就是说,map 数组中存储的都是指针,指向那些真正用来存储数据的各个连续空间(如图 1 所示)。
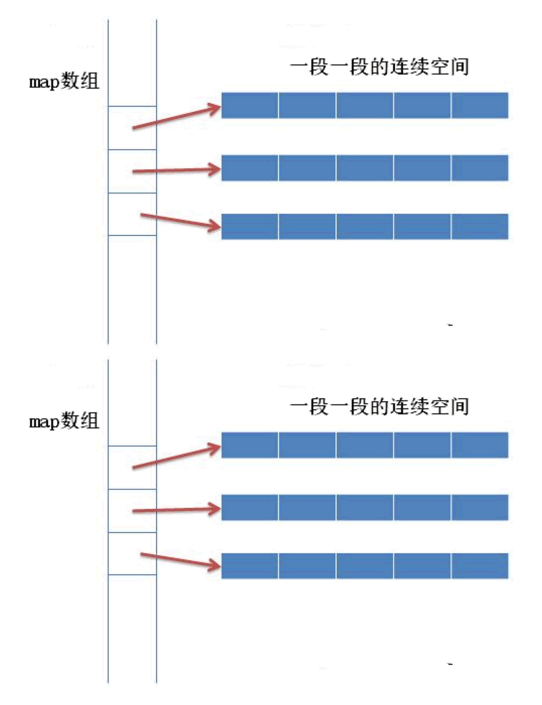
也就是说deque底层是一个动态开辟的二维数组,内部每个一维数组长度相等,不够时就开辟一个新的一维数组。
通过建立 map 数组,deque 容器申请的这些分段的连续空间就能实现“整体连续”的效果。
换句话说,当deque 容器需要在头部或尾部增加存储空间时,它会申请一段新的连续空间,同时在 map 数组的开头或结尾添加指向该空间的指针,由此该空间就串接到了 deque 容器的头部或尾部。
map 数组第一维初始值为2(一开始有2行),扩容时以2倍的方式进行扩容(2行变4行),扩容后,原来第二维的数组从新的二维数组的第一位下标oldsize / 2的位置开始存放(原内容复制到二维数组的第1、2行,从0行开始),上下都预留相同的空行,方便支持deque首尾元素的添加。