1. 启程
JSON 只包含 6 种数据类型
- null: 表示为 null
- boolean: 表示为 true 或 false
- number: 一般的浮点数表示方式
- string: 表示为 "..."
- array: 表示为 [ ... ]
- object: 表示为 { ... }
宏的编写技巧:反斜线代表该行未结束,会串接下一行。而如果宏里有多过一个语句(statement),就需要用 do { /.../ } while(0) 包裹成单个语句 否则预处理之后会出错 容易超出作用域
使用__FILE__和__LINE__可以打印语句所在文件 和 所处位置
通过预编译命令#define将其插入到使用位置 则可以实现打印具体错误位置的功能
测试驱动开发(test-driven development, TDD),它的主要循环步骤是:
- 加入一个测试。
- 运行所有测试,新的测试应该会失败。
- 编写实现代码。
- 运行所有测试,若有测试失败回到3。
- 重构代码。
- 回到 1。
断言的使用: 如果那个错误是由于程序员错误编码所造成的(例如传入不合法的参数),那么应用断言;如果那个错误是程序员无法避免,而是由运行时的环境所造成的,就要处理运行时错误(例如开启文件失败)。
2. 解析数字
重构:在不改变代码外在行为的情况下,对代码作出修改,以改进程序的内部结构。
通过内置的库函数 strtod()可以将字符串转换为浮点数 当值溢出时 返回定义在math.h头文件中的HUGE_VAL或-HUGE_VAL
C 的注释不支持嵌套(nested),而 #if ... #endif 是支持嵌套的。代码中已有注释时,用 #if 0 ... #endif 去禁用代码是一个常用技巧,而且可以把 0 改为 1 去恢复。
科学计数法的指数部分没有对前导零作限制 1E012 也是合法的
整数不容许前导零(leading zero),是因为更久的 JavaScript 版本容许以前导零来表示八进位数字,如 052 == 42,这种八进位常数表示方式来自于 C 语言。
禁止前导零避免了可能出现的歧义。但是在指数里就不会出现这个问题。
3. 解析字符串
JSON中也是通过双引号来界定字符串的 通过转义字符\"可以在字符串中出现双引号
一个值不可能同时为数字和字符串,因此我们可使用 C 语言的 union 来节省内存

通过realloc的方式确实能够改变原数组的尺寸。给用户的感受,就好像我的数组根据要求扩大或缩小了一样。
然而,底层实现可以知道,我们要分情况讨论:
就拿扩大来说,并不是在原数组的地址空间基础上,继续往后按照我们的意愿去扩展。因为,我们并不能保证拟扩展的地址空间上,是否有其他程序已经先行占用了?如果拟扩展地址空间上没有占用,那么后续扩展的内容调整后的内存空间和原来的内存空间,保持同一内存始址。
否则,程序会在内存的堆区重新找一块空闲的地址空间,并返回新的内存始址。所以,realloc返回的指针很可能指向一个新的地址。
realloc(p, size) 的功能是,分配一块大小为size的内存,并将p所指的内容复制过来(如果空间变大)并将重新分配的内存指针返回
c->stack 始终指向内存开头,
c->top 可以说是已使用大小 指向栈顶
c->size 表示c->stack指向的这块内存的大小。
Windows 下的内存泄漏检测方法
在 Windows 下,可使用 Visual C++ 的 C Runtime Library(CRT) 检测内存泄漏
首先,我们在两个 .c 文件首行插入这一段代码:
# ifdef _WINDOWS
# define _CRTDBG_MAP_ALLOC
# include <crtdbg.h>
# endif
并在 main() 开始位置插入:
int main(){
# ifdef _WINDOWS
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF |_CRTDBG_LEAK_CHECK_DF);
# endif
在输出会看到内存泄漏信息:

这正是我们在单元测试中,先设置字符串,然后设布尔值时没释放字符串所分配的内存。比较麻烦的是,它没有显示调用堆栈。从输出信息中 ... {79} ... 我们知道是第 79 次分配的内存做成问题,我们可以加上 _CrtSetBreakAlloc(79); 来调试,那么它便会在第 79 次时中断于分配调用的位置,那时候就能从调用堆栈去找出来龙去脉。
总的来说,就是先通过crt查看到第几次分配内存泄露,然后再用_CrtSetBreakAlloc函数中断于该位置具体分析调用堆栈
4. Unicode
为了制定一套多语言的统一编码系统,多个机构成立了 Unicode 联盟,在 1991 年释出 Unicode 1.0,收录了 24 种语言共 7161 个字符。
在四分之一个世纪后的 2016年,Unicode 已释出 9.0 版本,收录 135 种语言共 128237 个字符。
这些字符被收录为统一字符集(Universal Coded Character Set, UCS),每个字符映射至一个整数码点(code point),码点的范围是 0 至 0x10FFFF,码点又通常记作 U+XXXX,当中 XXXX 为 16 进位数字。例如 劲 → U+52B2、峰 → U+5CF0。很明显,UCS 中的字符无法像 ASCII 般以一个字节存储。
因此,Unicode 还制定了各种储存码点的方式,这些方式称为 Unicode 转换格式(Uniform Transformation Format, UTF)。现时流行的UTF 为 UTF-8、UTF-16 和 UTF-32。
每种 UTF 会把一个码点储存为一至多个编码单元(code unit)。例如 UTF-8 的编码单元是 8 位的字节、UTF-16 为 16 位、UTF-32 为 32 位。
除 UTF-32 外,UTF-8 和 UTF-16 都是可变长度编码。
UTF-8 的优势:
- 它采用字节为编码单元,不会有字节序(endianness)的问题。
- 每个 ASCII 字符只需一个字节去储存。
- 如果程序原来是以字节方式储存字符,理论上不需要特别改动就能处理 UTF-8 的数据。
JSON字符串中的 \uXXXX 是以 16 进制表示码点 U+0000 至 U+FFFF
4 位的 16 进制数字只能表示 0 至 0xFFFF,但 UCS 的码点是从 0 至 0x10FFFF,那怎么能表示多出来的码点?
U+0000 至 U+FFFF 这组 Unicode 字符称为基本多文种平面(basic multilingual plane, BMP),还有另外 16 个平面。
那么 BMP 以外的字符,JSON 会使用代理对(surrogate pair)表示 \uXXXX``\uYYYY。
在 BMP 中,保留了 2048 个代理码点。如果第一个码点是U+D800 至 U+DBFF,我们便知道它是代码对的高代理项(high surrogate),之后应该伴随一个 U+DC00 至 U+DFFF 的低代理项(low surrogate)。
然后,我们用下列公式把代理对 (H, L) 变换成真实的码点:
codepoint = 0x10000 + (H − 0xD800) × 0x400 + (L − 0xDC00)
UTF-8 的编码单元为 8 位(1 字节),每个码点编码成 1 至 4 个字节。它的编码方式很简单,按照码点的范围,把码点的二进位分拆成 1 至最多 4 个字节:
| 码点范围 | 码点位数 | 字节1 | 字节2 | 字节4 | 字节4 |
|---|---|---|---|---|---|
U+0000~U+007F |
7 | 0xxxxxxx | |||
U+0080~U+07FF |
11 | 110xxxxx | 10xxxxxx | ||
U+0800~U+FFFF |
16 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000~U+10FFF |
21 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
这个编码方法的好处之一是,码点范围 U+0000 ~ U+007F 编码为一个字节,与 ASCII 编码兼容。这范围的 Unicode 码点也是和 ASCII 字符相同的。因此,一个 ASCII 文本也是一个 UTF-8 文本。
我们举一个例子解析多字节的情况, 欧元符号→U+20AC:
U+20AC在U+0800~U+FFFF的范围内,应编码成3个字节。U+20AC的二进位为 10000010101100- 3个字节的情况我们要16位的码点,所以在前面补两个0,成为 010000010101100
- 按上表把二进位分成3组: 0010, 000010, 101100
- 加上每个字节的前缀: 1100010, 10000010, 10101100
- 用十六进位表示即:
0xE2,0x82,0xAC
将整数转换为utf-8字符代码 注意utf-8中可以用多个字节存储一个字符 即存入多个不同字符 解码时会自动转换为utf-8字符
为什么要做 x & 0xFF 这种操作呢?这是因为 u 是 unsigned 类型,一些编译器可能会警告这个转型可能会截断数据
static void lept_encode_utf8 (lept_ context* C,unsigned u) {
if (u <= 0x7F) PUTC(C, u & 0xFF);
else if (u <= 0x7FF) {
PUTC(C, 0xC0 | ((u >> 6) & 0xFF));
PUTC(C, 0x88 | ( u & ex3F));
}
else if (u <= 0xFFFF) {
PUTC(C, 0xE0| ((u >> 12) & 0xFF));
PUTC(C, 0x80| ((u >> 6) & 0x3F));
PUTC(E, 0x80| ( u & 0x3F));
}
else {
assert(u <= 0x10FFFF);
PUTC(C, 0xF0| ((u >> 18) & 0xFF));
PUTC(C, 0x80| ((u >> 12) & 0x3F));
PUTC(C, 0x88| ((u >> 6) & 0x3F));
PUTC(C, 0x80| ( u & 0x3F));
}
}
5. 数组
struct{
lept_value* e;
size_t size, capacity;
} a;
/* array: elements, element count, capacity */
一个 JSON 数组可以包含零至多个元素,而这些元素也可以是数组类型。换句话说,数组可以表示嵌套(nested)的数据结构。
对于 JSON 数组,也可以用与解析字符串相同的方法,而且,可以用同一个堆栈!只需要把每个解析好的元素压入堆栈,解析到数组结束时,再一次性把所有元素弹出,复制至新分配的内存之中。
for (;;) {
/* bug! */
lept_value* e = lept_context_push(c, sizeof(lept_value));
lept_init(e);
size++;
if ((ret = lept_parse_value(c, e)) != LEPT_PARSE_OK)
return ret;
/* ... */
}
这个 bug 源于压栈时,会获得一个指针 e,指向从堆栈分配到的空。
然后,程序对这个指针调用 lept_parse_value(c, e),这里会出现问题
因为 lept_parse_value() 及之下的函数都需要调用 lept_context_push(),而lept_context_push() 在发现栈满了的时候会用 realloc() 扩容。
这时候,我们上层的 e 就会失效,变成一个悬挂指针(dangling pointer),而且lept_parse_value(c, e) 会通过这个指针写入解析结果,造成非法访问。
这个bug非常不明显 只有当栈满时才会发生 因此在使用指针时 必须明白指针的生存周期
使用malloc 就需要使用free将其释放
而在解析array时使用了malloc 没释放 因此必须在解析完毕 不使用时释放 也就是在lept_free()处释放
6. 对象
在软件工程中,代码重构(code refactoring)是指在不改变软件外在行为时,修改代码以改进结构。
代码重构十分依赖于单元测试,因为我们是通过单元测试去维护代码的正确性。有了足够的单元测试,我们可以放胆去重构,尝试并评估不同的改进方式,找到合乎心意而且能通过单元测试的改动,我们才提交它。
JSON 对象以花括号 {}(U+007B、U+007D)包裹表示,另外 JSON 对象由对象成员(member)组成,而 JSON 数组由 JSON 值组成。
struct{
lept_member* m;
size_t size,capacity;
} o;
/* object: members, member count, capacity */
所谓对象成员,就是键值对,键必须为 JSON 字符串,然后值是任何 JSON 值,中间以冒号 :(U+003A)分隔。
语法如下
member = string Ws %x3A Ws value
object = %x7B ws[ member *( ws %x2C Ws member )] Ws %x7D
如果我们成功地解析整个成员,那么就要把 m.k 设为空指针,其意义是说明该键的字符串的拥有权已转移至栈,之后如遇到错误,我们不会重覆释放栈里成员的键和这个临时成员的键。
7. 生成器
JSON 生成器(generator)负责与解析器相反的事情,就是把树形数据结构转换成 JSON 文本。这个过程又称为「字符串化(stringify)」。
在实现 JSON 解析时,我们加入了一个动态变长的堆栈,用于存储临时的解析结果。而现在,我们也需要存储生成的结果,所以最简单是再利用该数据结构,作为输出缓冲区。
使用 sprintf("%.17g", ...) 来把浮点数转换成文本。"%.17g" 是足够把双精度浮点转换成可还原的文本。
int sprintf(char *str, const char *format, ...) 发送格式化字符串format输出到 str 所指向的字符串。
如果成功,则返回写入的字符总数,不包括字符串追加在字符串末尾的空字符。如果失败,则返回一个负数。
sprintf("%04x", ...)可以用来用将16进制数转换为文本
%04x 中x表示以小写的十六进制数输出;4表示输百出的十六进制数的宽度是4个字符;0表示输出的十六进制数中,不足4个字符的部分,用“0”来补度充,以达到4个字符的宽度。
函数优化
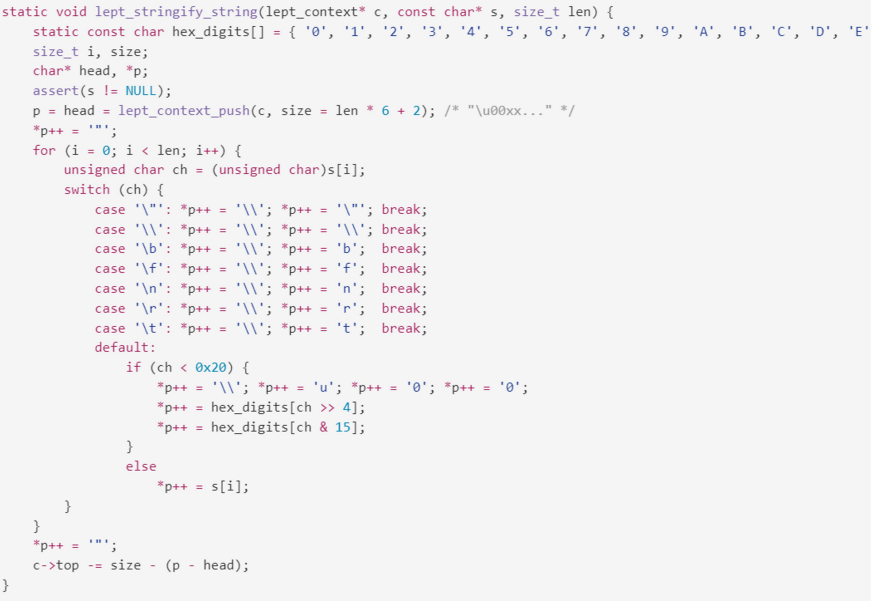
lept_stringify_string() 实现中,每次输出一个字符/字符串,都要调用lept_context_push()。如果我们使用一些性能剖测工具,也可能会发现这个函数消耗较多 CPU。

中间最花费时间的,应该会是 (1) 需要计算而且作分支检查。
一个优化的点子是,预先分配足够的内存,每次加入字符就不用做这个检查了。
我们可以看到,每个字符可生成最长的形式是 \u00XX,占 6 个字符,再加上前后两个双引号,也就是共 len * 6 + 2 个输出字符。
那么,使用 char* p = lept_context_push() 作一次分配后,便可以用 *p++ = c 去输出字符了。
最后,再按实际输出量调整堆栈指针。
要注意的是,很多优化都是有代价的。这个优化采取空间换时间的策略,对于只含一个字符串的JSON,很可能会分配多 6 倍内存;但对于正常含多个值的 JSON,多分配的内存可在之后的值所利用,不会造成太多浪费。
另一个小优化点是,自行编写十六进位输出,避免 printf() 内解析格式的开销
8. 常见的json解析工具
Jackson
Jackson库(http://jackson.codehaus.org),是基于java语言的开源json格式解析工具功能全面,提供多种模式的json解析方式,“对象绑定”使用方便,利用注解包能为我们开发提供很多便利。
性能较高,“流模式”的解析效率超过绝大多数类似的json包。
FastJson
Fastjson 是一个 Java 库,可以将 Java 对象转换为 JSON 格式,当然它也可以将 JSON 字符串转换为 Java 对象。
Fastjson 可以操作任何 Java 对象,即使是一些预先存在的没有源码的对象。
提供服务器端、安卓客户端两种解析工具,性能表现较好。
9. 自我学习开发的C++版本
cpp_json
本项目是基于 json-tutorial 教程 个人学习后开发的c++版本
项目特点
- 通过cmake构建跨平台使用的代码
- 相较于原教程使用指针管理内存的方法,本项目使用C++的容器来管理动态内存,在可读性和安全性上都更高
- 本项目相较于原项目在某些处理上有所不同
- 在字符串处理上:本项目由于使用内置的string而不解析\0字符
- 在数字溢出方面:本项目采用与C++本身一致的处理机制,对于溢出的数字,令其为对应的极限值,不进行报错
- 本项目使用标准库的 map 容器实现了JSON_OBJECT,因此可以方便的直接调用map的函数来获取键值情况、查找key等
- 使用 vector 容器实现了JSON_ARRAY 进行动态内存的管理
- 同时 本项目还通过重载运算符的方法实现了错误情况打印, JSON对象打印内容和JSON对象拷贝构造,拷贝赋值运算符,以及直接使用运算符进行JSON对象的比较运算
- 定义了JSON对象的swap操作
项目结构
- CMakeLists.txt:CMake配置文件
- cpp_json.cpp:测试文件,包含对于各项解析的单元测试
- cpp_json.h:头文件,对存储数据结构定义和解析函数定义
- parse.cpp:实现头文件中定义的解析函数